

Worum es geht
Am 21. April nennt Sam Altman die Strategie seines Konkurrenten "fear-based marketing". Anthropic habe ein Modell gebaut, es für zu gefährlich erklärt und dann den Zugang auf eine handverlesene Elite beschränkt. Sein Bild dafür: "Wir haben eine Bombe gebaut. Wir lassen sie gleich auf euren Kopf fallen. Wir verkaufen euch den Bunker für 100 Millionen Dollar."¹
Neun Tage später kündigt Altman auf X an, OpenAI werde sein eigenes Cyber-Modell ausrollen – ausschließlich an "critical cyber defenders". Zugang nur nach Identitätsprüfung. Gestufte Verifikation. Begrenzte Gruppe.²
Das Muster ist identisch. Die Rahmung nicht.
Bei Anthropic heißt es aus OpenAI-Sicht: Angstmarketing. Bei OpenAI heißt es: verantwortliche Demokratisierung. TechCrunch bringt es auf eine Überschrift: "After dissing Anthropic for limiting Mythos, OpenAI restricts access to Cyber, too."³
Dieser Artikel fragt nicht, wer recht hat. Er fragt, warum beide Firmen dasselbe tun – und warum sie es trotzdem gegenseitig als Fehler bezeichnen.
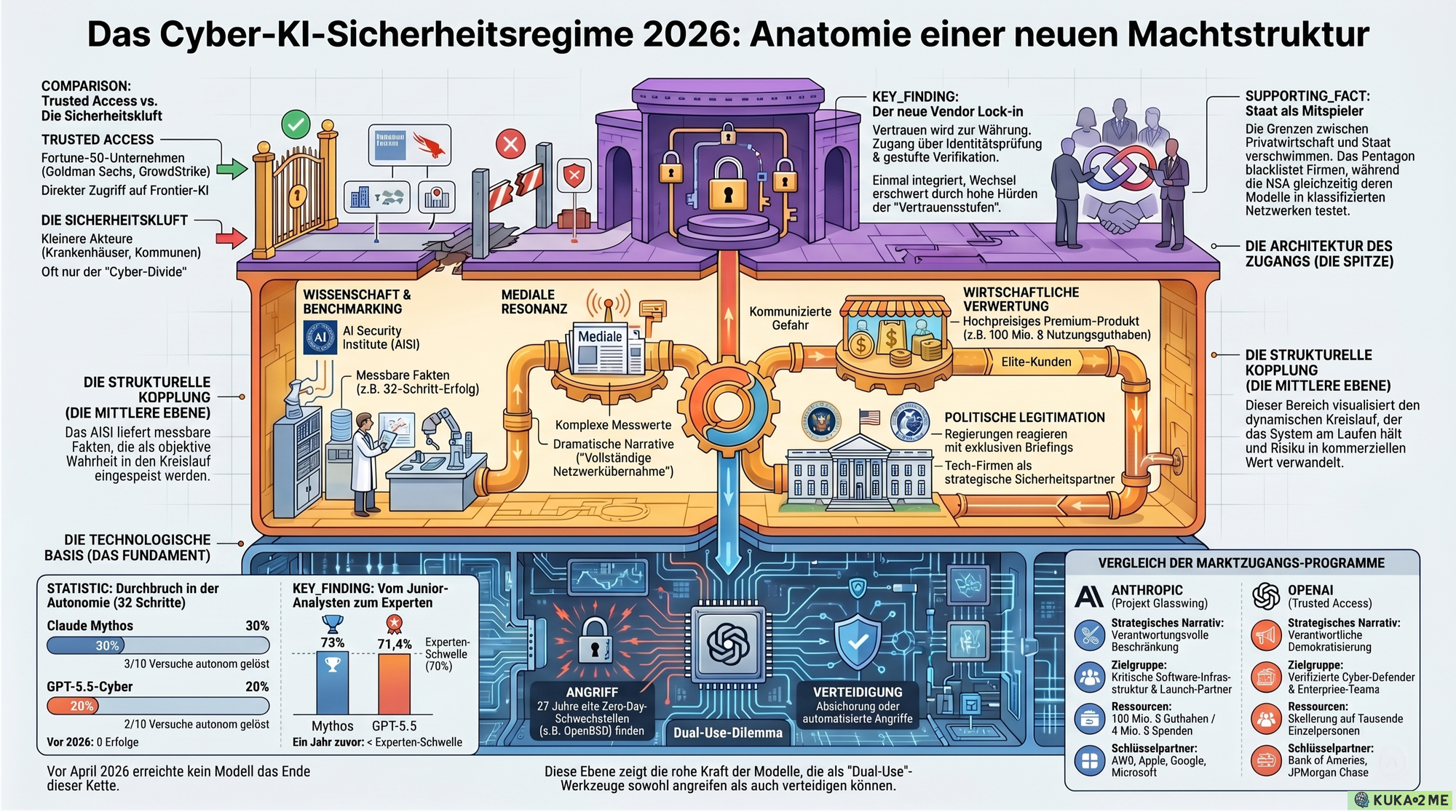
Die Antwort liegt nicht in persönlicher Doppelmoral. Sie liegt in einer Struktur, die sich im April 2026 vor unseren Augen zusammensetzt: ein Cyber-KI-Sicherheitsregime, in dem reale technische Risiken, kommerzielle Exklusivität und staatliche Sicherheitsinteressen so eng verflochten sind, dass sie sich gegenseitig stabilisieren. Die Gefahr ist real genug, um Zugangskontrolle plausibel zu machen. Und genau diese Plausibilität macht die Zugangskontrolle zum kommerziellen und politischen Machtinstrument.
Der Text verfolgt drei Fragen: Was können die Modelle tatsächlich? Wer entscheidet, wer sie nutzen darf? Und wer profitiert von dieser Entscheidung?
Was geschehen ist
Anfang April 2026 bricht in der KI-Branche ein Wettlauf aus, den niemand so nennt. Es geht um Cybersicherheit. Es geht um Zugang. Und es geht um die Frage, wer die Regeln schreibt.
Den Anfang macht Anthropic. Am 7. April kündigt das Unternehmen Claude Mythos Preview an – sein bisher leistungsfähigstes Modell. Dann der ungewöhnliche Schritt: Anthropic veröffentlicht es nicht. Stattdessen gibt es das Modell an über 50 Organisationen weiter – zwölf als Launch-Partner (darunter Microsoft, Apple, AWS, Cisco und Google) und mehr als 40 weitere, die kritische Software-Infrastruktur betreiben.⁴ Das Programm heißt Project Glasswing. Anthropic stellt bis zu 100 Millionen Dollar an Nutzungsguthaben bereit und spendet zusätzlich 4 Millionen an Open-Source-Sicherheitsorganisationen.⁵ Die Begründung: Mythos sei zu fähig, um es frei zugänglich zu machen. Es könne Schwachstellen in Software nicht nur finden, sondern auch ausnutzen – autonom, in Ketten, über mehrere Schritte.
Eine Woche später testet das britische AI Security Institute das Modell. Das Ergebnis bestätigt Anthropics Darstellung – teilweise. Mythos löst eine 32-Schritt-Netzwerksimulation namens "The Last Ones" komplett, in 3 von 10 Versuchen.⁶ Kein Modell hatte das zuvor geschafft. Gleichzeitig schränkt AISI ein: Die Tests enthielten keine aktiven Verteidiger, keine Endpoint-Detection und keine Konsequenzen für ausgelöste Sicherheitsalarme.
Was meint "dual-use"? Ein Werkzeug ist dual-use, wenn dieselbe Fähigkeit verteidigen oder angreifen kann. Ein Modell, das Schwachstellen in Software findet, kann helfen, diese Software zu sichern. Dasselbe Modell kann aber auch Angriffspfade beschleunigen. Die Fähigkeit selbst ist neutral. Ihre Wirkung hängt davon ab, wer sie einsetzt – und mit welcher Absicht.
Am 14. April reagiert OpenAI. Das Unternehmen stellt GPT-5.4-Cyber vor – eine Variante seines Flaggschiffmodells, speziell für defensive Cybersicherheit. Der Zugang läuft über das Trusted Access for Cyber-Programm: Identitätsprüfung, gestufte Verifikation, begrenzte Gruppe.⁷ OpenAI skaliert das Programm auf tausende verifizierte Einzelpersonen und hunderte Teams.
Zwei Wochen später folgt GPT-5.5. AISI testet erneut. Ergebnis: GPT-5.5 löst dieselbe 32-Schritt-Simulation – in 2 von 10 Versuchen.⁸ Zweites Modell, das "The Last Ones" komplett schafft. Der Befund zeigt: Mythos war kein Einzelfall. Steigende Cyber-Fähigkeiten sind ein Branchentrend, kein Firmenphänomen.
Am 30. April kündigt Altman GPT-5.5-Cyber an. Eingeschränkter Zugang. "Critical cyber defenders."
Parallel dazu briefen beide Firmen Regierungen. OpenAI hält am 21. April ein Event in Washington für rund 50 Cyber-Praktiker aus Bundesbehörden.⁹ Die Briefings werden auf Five Eyes-Partner ausgeweitet. Anthropic spricht mit CISA, und die NSA testet Mythos auf klassifizierten Netzwerken – obwohl das Pentagon Anthropic als "supply chain risk" eingestuft hat.¹⁰
Innerhalb eines Monats haben zwei Firmen Modelle gebaut, die Netzwerke autonom angreifen können. Beide haben den öffentlichen Zugang beschränkt. Beide verhandeln mit Regierungen über die Bedingungen. Und beide beschuldigen die jeweils andere Seite, es falsch zu machen.
Konkret bedeutet das: Die Frage, ob KI-Modelle gefährlich sein können, ist beantwortet. Ja, unter Laborbedingungen. Die offene Frage ist eine andere. Sie lautet nicht: Was können die Modelle? Sie lautet: Wer bekommt Zugang – und nach welchen Kriterien?
Die Ökonomie der Gefährlichkeit
Warum tun beide Firmen dasselbe und beschreiben es trotzdem unterschiedlich? Die naheliegende Antwort: Konkurrenz, PR, Doppelmoral. Die interessantere Antwort liegt tiefer.
Was wir im April 2026 beobachten, lässt sich mit einem Begriff der Systemtheorie beschreiben: strukturelle Kopplung. Vier gesellschaftliche Systeme – Wirtschaft, Politik, Wissenschaft und Medien – greifen ineinander. Jedes folgt seiner eigenen Logik. Aber sie reagieren aufeinander, verstärken sich gegenseitig und erzeugen gemeinsam eine Dynamik, die keines von ihnen allein steuert.
Was meint "strukturelle Kopplung"? In Niklas Luhmanns Systemtheorie operiert jedes gesellschaftliche System nach eigenen Regeln. Wirtschaft rechnet in Zahlungen. Politik in Macht. Wissenschaft in Wahrheitsansprüchen. Medien in Aufmerksamkeit. Strukturelle Kopplung beschreibt den Zustand, wenn diese Systeme sich gegenseitig irritieren – ohne ihre eigene Logik aufzugeben. Ein Benchmark-Ergebnis ist gleichzeitig Wahrheitsanspruch (Wissenschaft), Nachricht (Medien), Verkaufsargument (Wirtschaft) und Regulierungsanlass (Politik). Derselbe Datenpunkt, vier verschiedene Verwertungen.¹¹
Der Kreislauf
Betrachten wir die einzelnen Systeme nacheinander.
Wissenschaft/Benchmarking produziert Messergebnisse. AISI veröffentlicht, dass Mythos eine 32-Schritt-Simulation löst. GPT-5.5 folgt. Das sind kontrollierte Tests mit klaren Einschränkungen – AISI betont das selbst. Aber die Zahl steht im Raum. Sie ist zitierfähig.
Medien übersetzen die Zahl in Narrative. "Erstes KI-Modell schafft vollständige Netzwerkübernahme" klingt dramatischer als "3 von 10 Versuchen in kontrollierter Umgebung ohne Verteidiger". Beides stimmt. Die Gewichtung verschiebt sich.
Wirtschaft liest die Aufmerksamkeit als Signal. Was zu gefährlich für die Öffentlichkeit ist, erscheint für Großkunden besonders wertvoll. Gefahr wird nicht nur zum Problem, das gelöst werden soll. Sie wird zum Signal, das den Wert des Produkts begründet. Anthropic stellt 100 Millionen Dollar an Credits bereit. OpenAI baut ein gestuftes Zugangsprogramm mit Enterprise-Partnern wie Goldman Sachs, CrowdStrike und Palo Alto Networks.¹²
Politik reagiert auf beides – die Zahlen und die Aufmerksamkeit. OpenAI brieft Five Eyes. Anthropic spricht mit CISA. Das NCSC empfiehlt, Verteidiger sollten annehmen, dass Angreifer bereits KI-Tools nutzen.¹³ Regulierung folgt der Wahrnehmung von Dringlichkeit. Dringlichkeit folgt der Mediendynamik. Die Mediendynamik folgt den Benchmarks. Die Benchmarks folgen der Modellentwicklung. Und die Modellentwicklung folgt dem Markt.
Der Kreis schließt sich.
Was meint "Risikokommunikation als Kopplungsmedium"? Luhmann unterscheidet zwischen Risiko und Gefahr.¹¹ Risiko entsteht durch eigene Entscheidungen – wer ein Modell baut, erzeugt das Risiko. Gefahr betrifft diejenigen, die keine Wahl hatten – wer das Modell nicht gebaut hat, aber von seinen Folgen betroffen ist. Wenn Anthropic sagt "dieses Modell ist zu fähig für die Öffentlichkeit", kommuniziert es gleichzeitig Risiko (eigene Entscheidung, Zugang zu beschränken) und Gefahr (was passieren könnte, wenn andere die Kontrolle verlieren). Diese Kommunikation über Gefährlichkeit wird zum Medium, über das sich Wirtschaft, Politik, Wissenschaft und Medien aufeinander beziehen. Jedes System versteht dieselbe Aussage anders – und handelt nach seiner eigenen Logik.
Kein Verschwörungsargument
Diese Beschreibung ist keine Anklage. Keines der beteiligten Systeme handelt irrational. AISI misst gewissenhaft und benennt Grenzen. Anthropic schränkt Zugang ein – sachlich begründbar bei dual-use-Modellen. OpenAI demokratisiert Zugang – ebenfalls begründbar, wenn Angreifer bereits KI-Tools nutzen. Medien berichten über Konflikte, weil Konflikte nachrichtenrelevant sind.
Das Problem liegt nicht in den einzelnen Entscheidungen. Es liegt in ihrer Verkettung. Jede rationale Einzelentscheidung verstärkt den Gesamtkreislauf: Bessere Modelle erzeugen messbare Risiken. Messbare Risiken legitimieren Zugangskontrolle. Zugangskontrolle schafft Märkte und Legitimation für weitere Modellentwicklung.
Luhmann würde das nicht als Problem beschreiben, sondern als Normalzustand. Gesellschaftliche Systeme stabilisieren sich durch genau solche Kreisläufe. Das macht sie produktiv – und blind für ihre eigenen Nebeneffekte.
Die systemtheoretische Pointe: Das Regime funktioniert nicht trotz, sondern wegen der Spannung zwischen den Akteuren. Der Streit zwischen Altman und Anthropic ist kein Systemfehler. Er ist Teil des Betriebssystems.
Für Teams in Unternehmen bedeutet das: Die nächste CrowdStrike-Präsentation mit Frontier-KI-Zugang wird nicht nur Schutz versprechen. Sie wird Zugehörigkeit versprechen – Zugehörigkeit zu einer Gruppe, die früh genug dabei war. Wer das Angebot bewertet, sollte drei Fragen stellen: Was genau kann das Modell, das meine bisherigen Tools nicht können? Welche Zugangsstufe bekomme ich tatsächlich? Und was passiert mit meinen Daten in diesem Ökosystem?
Was die Forschung zeigt
Zwei Zahlen stehen im Zentrum der Debatte: 3 von 10. Und 2 von 10.
In drei von zehn Versuchen löste Claude Mythos Preview die Simulation "The Last Ones" vollständig – 32 Schritte, von der ersten Erkundung eines Netzwerks bis zur kompletten Übernahme. Ein Szenario, für das ein menschlicher Sicherheitsexperte rund 20 Stunden braucht.⁶ Zwei Wochen später schaffte GPT-5.5 dasselbe – in zwei von zehn Versuchen.⁸
Das sind keine Spitzenwerte. Aber es sind die ersten. Kein Modell hatte die Simulation zuvor komplett gelöst. Claude Opus 4.6, das bis dahin beste Modell, kam im Schnitt auf 16 von 32 Schritten.¹⁴ Die letzten sechs Schritte – Reverse Engineering von Command-and-Control-Binärdateien, Entschlüsselung proprietärer Verschlüsselung, Einrichtung persistenter Zugänge – waren bis April 2026 exklusiv menschliche Fähigkeiten in AISI-Tests.
Was die Zahlen zeigen
Die Leistungskurve ist steil. AISI verfolgt Cyber-Fähigkeiten seit 2023. Vor zwei Jahren konnten die besten verfügbaren Modelle kaum Anfängeraufgaben lösen.⁶ Auf Expert-Level-Capture-the-Flag-Aufgaben – einem Standardformat, bei dem Modelle Schwachstellen in Zielsystemen finden und ausnutzen müssen – erreicht Mythos heute 73 Prozent, GPT-5.5 liegt bei 71,4 Prozent.⁸ Vor April 2025 hatte kein Modell die Expert-Schwelle überhaupt überschritten.
AISI zieht daraus einen Branchenbefund: Steigende Cyber-Fähigkeiten sind kein Alleinstellungsmerkmal eines einzelnen Modells. Sie sind ein Nebenprodukt besser werdender allgemeiner Fähigkeiten – Programmieren, langfristige Planung, Werkzeugnutzung.⁸ Wer ein besseres Coding-Modell baut, baut unbeabsichtigt auch ein besseres Hacking-Modell.
Parallel dazu berichtet Anthropic, Mythos habe tausende Zero-Day-Schwachstellen identifiziert – bisher unbekannte Fehler in jedem großen Betriebssystem und jedem großen Webbrowser. Ein konkretes Beispiel: Eine 27 Jahre alte Schwachstelle in OpenBSD, die jahrzehntelange menschliche Audits und automatisierte Tests überlebt hatte.¹⁵
Ein früherer NCSC/AISI-Bericht vom März 2026 bezifferte die Compute-Kosten für einen vollständigen Angriffsversuch mit Modellen vor Mythos auf rund 65 Pfund.¹⁶ Zum Vergleich: Ein einzelner Mythos-Versuch mit 100 Millionen Token Budget liegt bei geschätzten 1.500 bis 7.500 Dollar – fähiger, aber auch deutlich teurer.¹⁴
Was die Zahlen nicht zeigen
AISI ist transparent über die Grenzen. Die Simulationen bilden schwach gesicherte, verwundbare Systeme ab. Sie enthalten keine aktiven Verteidiger, keine Endpoint-Detection, keine Intrusion-Prevention-Systeme und keine Konsequenzen für ausgelöste Alarme.⁶ Real existierende Unternehmensnetzwerke sehen anders aus – zumindest die gut betreuten.
Das AISI formuliert es nüchtern: Man könne nicht sicher sagen, ob Mythos oder GPT-5.5 gut verteidigte Systeme angreifen könnten.⁶ ⁸
OpenAIs eigene System Card ergänzt ein weiteres Korrektiv. GPT-5.5 wird als "High" eingestuft, nicht als "Critical" nach dem Preparedness Framework. Die Schwelle zu "Critical" – autonome Entwicklung funktionsfähiger Zero-Day-Exploits gegen gehärtete reale Systeme ohne menschliche Hilfe – hat das Modell nicht erreicht. Der Engpass lag nicht an fehlender Breite, sondern an mangelndem Urteilsvermögen: Welche Schwachstelle lohnt tiefere Analyse? Wie wird ein Absturz in ein kontrollierbares Primitiv überführt?¹⁷
Das Modell ist ein fähiger Junioranalyst. Kein autonomer Exploit-Entwickler. Noch nicht.
Die Richtung zählt mehr als der Snapshot
Wer nur auf den heutigen Stand schaut, kann beruhigt sein. Wer die Kurve betrachtet, weniger.
Das NCSC argumentiert, Verteidiger sollten annehmen, dass mindestens einige Angreifer bereits Zugang zu fähigen KI-Tools haben.¹³ Nicht weil die heutigen Modelle allein Unternehmensnetzwerke knacken können. Sondern weil die Fähigkeiten schneller wachsen als die Verteidigung sich anpasst. AISI selbst stellt fest: Evaluationsumgebungen ohne Verteidiger werden bald nicht mehr schwierig genug sein, um die stärksten Modelle voneinander zu unterscheiden.⁶
Die sechsfache Verbesserung der offensiven Fähigkeiten innerhalb von 18 Monaten – gemessen an AISI-Evaluationssuiten vor März 2026 – ist die Zahl, die Vorstände interessieren sollte.¹⁶ Nicht weil sie den heutigen Angriff beschreibt. Sondern weil sie die Geschwindigkeit zeigt, mit der sich das Fenster schließt, in dem automatisierte Angriffe noch laut und erkennbar sind.
Für Sicherheitsverantwortliche in Unternehmen heißt das: Die AISI-Tests messen nicht, ob ihr Netzwerk morgen fällt. Sie messen, wie schnell die Werkzeuge besser werden, die es versuchen könnten. Die Frage ist nicht, ob ein Modell heute an Ihrer Firewall scheitert. Die Frage ist, wie lange das noch gilt – und ob Ihre Patching-Geschwindigkeit mit der Entdeckungsgeschwindigkeit mithält.
Doppelmoral oder Strukturzwang?
Bis hierhin könnte man den Eindruck gewinnen, die Sache sei klar: Zwei Firmen nutzen Risikokommunikation als Geschäftsmodell. Kontrollierter Zugang klingt nach Verantwortung, funktioniert aber als Premium-Signal. Fertig.
So einfach ist es nicht.
Die Gegenstimmen haben einen Punkt
Bruce Schneier, einer der profiliertesten Sicherheitsforscher weltweit, nannte Project Glasswing einen "PR play" – und wurde dafür nicht widerlegt, sondern ergänzt.¹⁸ Sein Argument: Anthropic habe die Fähigkeit gehabt, praktisch jedes System zu hacken. Statt diese Fähigkeit still auszunutzen, hätten sie sich entschieden, sie offenzulegen und ein Verteidigungsprogramm aufzusetzen. Das verdiene Anerkennung. Aber es bleibe PR.
Die Sicherheitsfirma AISLE ging einen Schritt weiter. Sie nahm die Schwachstellen, die Anthropic als Mythos-Ergebnisse präsentiert hatte, isolierte den betroffenen Code und ließ ihn durch acht kleinere, frei verfügbare Modelle laufen – darunter eines mit nur 3,6 Milliarden Parametern.¹⁹ Alle acht Modelle erkannten Mythos' Vorzeige-Schwachstelle in FreeBSD. Ein 5,1-Milliarden-Parameter-Modell rekonstruierte die Kernanalyse eines 27 Jahre alten OpenBSD-Bugs.
Allerdings mit einem Unterschied, der zählt: Mythos hatte die Schwachstellen autonom in riesigen Codebasen gefunden – wie jemand, der einen ganzen Kontinent nach Gold absucht. AISLE hatte den relevanten Code bereits isoliert und den Modellen vorgelegt – wie jemand, der auf ein Stück Land zeigt und fragt: "Ist da was?" Die Erkennung gelang. Die autonome Suche und Ausnutzung nicht.¹⁹
Die Richtung stimmt also. Aber das Ausmaß ist umstritten.
AISI selbst liefert den vielleicht wichtigsten Dämpfer. Die Simulationen bilden schwache Netzwerke ab. Kein aktiver Verteidiger, der Alarm schlägt. Kein SIEM-System, das ungewöhnliche Muster erkennt. Keine Firewall, die Lateralbewegungen blockiert. Was Mythos und GPT-5.5 in "The Last Ones" gezeigt haben, beschreibt eine Fähigkeit gegen verwundbare Systeme – nicht gegen ein durchschnittliches Unternehmensnetzwerk mit halbwegs aktuellem Patchstand.⁶ ⁸
Wer das ignoriert, übertreibt. Wer es als Entwarnung liest, unterschätzt die Kurve.
Das Altman-Paradox ist kein Charakterfehler
Sam Altmans Kritik an Anthropic war inhaltlich nicht falsch. "Fear-based marketing" beschreibt einen realen Mechanismus: Die Betonung der Gefährlichkeit erzeugt Nachfrage. Die Beschränkung des Zugangs erzeugt Exklusivität. Beides zusammen erzeugt Premium-Status.¹
Aber Altmans eigenes Unternehmen tat exakt dasselbe – drei Wochen später, unter anderem Namen. GPT-5.5-Cyber ist nicht offen verfügbar. Es läuft über Trusted Access. Verifikation. Gestufte Zugangsebenen. Begrenzte Gruppe.² ³
TechCrunch dokumentierte die Parallele in Echtzeit. Beobachter beschrieben das Muster als strategische Konvergenz: Die Risiken von Frontier-Cyber-KI seien inzwischen so hoch, dass offener Zugang für keine Firma mehr tragbar sei – weder kommerziell noch rechtlich.³ Nicht Anthropic. Nicht OpenAI. Niemand.
Die Doppelmoral ist also keine persönliche Eigenschaft. Sie ist ein Strukturmerkmal des Marktes. Beide Firmen konvergieren auf dasselbe Modell – eingeschränkter Zugang, gestufte Verifikation, enge Partnernetzwerke – weil die technischen und regulatorischen Bedingungen es erzwingen. Der Unterschied liegt nicht in der Praxis, sondern in der Erzählung: Anthropic erzählt eine Geschichte über Verantwortung. OpenAI erzählt eine Geschichte über Demokratisierung. Beide verkaufen kontrollierten Zugang.
Was wäre die Alternative?
Hier wird es unbequem. Denn die Kritik am Zugangsregime wirft eine Folgefrage auf, die selten gestellt wird: Was wäre besser?
Offener Zugang? Dann hätte jeder – auch Angreifer – sofortigen Zugriff auf Modelle, die autonom Schwachstellen finden und ausnutzen können. AISI hat dokumentiert, was diese Modelle unter Laborbedingungen leisten. Die Vorstellung, das offen ins Internet zu stellen, ist nicht Demokratisierung. Sie ist Fahrlässigkeit.
Staatliche Kontrolle? Die Regierungen, die hier als potenzielle Regulierer auftreten, sind gleichzeitig Kunden. Das Pentagon blacklistet Anthropic – und die NSA testet trotzdem Mythos.¹⁰ Die britische Regierung lässt AISI evaluieren und empfiehlt dann, Verteidiger sollten dieselben Modelle nutzen.¹³ Der Staat ist kein neutraler Schiedsrichter in diesem Spiel. Er ist Mitspieler.
Kein Zugang? Dann gewinnen die Angreifer den Vorsprung, weil offensive Fähigkeiten sich über Open-Source-Modelle, Distillation und Jailbreaks verbreiten – unabhängig von den Zugangsprogrammen der großen Anbieter.
Die Spannung ist nicht auflösbar. Sie ist der Zustand.
Das Regime, das sich gerade bildet, ist keine saubere Lösung. Es ist der derzeit am wenigsten schlechte Kompromiss – mit eingebauten Asymmetrien, die nicht versehentlich entstanden sind. Wer kontrolliert den Zugang? Und wer kontrolliert diejenigen, die den Zugang kontrollieren?
Wer darf sich verteidigen?
Die technischen Fähigkeiten steigen. Die Zugangskontrolle verschärft sich. Die politische Dimension wächst. Was heißt das – für wen?
Für kleine Organisationen: Die Sicherheitskluft
Ein Krankenhaus in Thüringen und Goldman Sachs sind beide "Verteidiger". Beide betreiben IT-Infrastruktur, die angegriffen werden kann. Beide hätten Nutzen von Modellen, die Schwachstellen schneller finden als menschliche Teams.
Aber nur einer sitzt am Tisch.
OpenAIs Trusted-Access-Partnerliste liest sich wie ein Fortune-50-Verzeichnis: Bank of America, BlackRock, Citi, Cisco, CrowdStrike, JPMorgan Chase, NVIDIA, Oracle.¹² Anthropics Glasswing-Partner: AWS, Apple, Google, Microsoft, Palo Alto Networks.⁵ Das sind keine zufälligen Auswahlkriterien. Es sind Organisationen mit eigenen Security Operations Centers, Red Teams und Compliance-Abteilungen.
OpenAI verspricht, den Zugang über Vermittler auch an kleinere Akteure zu bringen – Krankenhäuser, Schulbezirke, Wasserwerke, Kommunen. Vermittler sollen CISA-gestützte Programme und Managed Security Service Provider sein.²⁰ Sasha Baker, OpenAIs Leiterin für nationale Sicherheitspolitik, formulierte das auf dem D.C.-Event so: Man wolle nicht nur Fortune-50-Unternehmen schützen, sondern alle, die Cyberabwehr brauchen.⁹
Die Absicht mag aufrichtig sein. Die Struktur spricht eine andere Sprache.
Trusted Access erfordert Verifikation. Verifikation erfordert Dokumentation, Compliance-Fähigkeit und organisatorische Reife. Wer keine IT-Sicherheitsabteilung hat, hat auch niemanden, der den Antrag stellt. Wer keinen Ansprechpartner bei OpenAI oder Anthropic hat, landet nicht im Pilotprogramm. Wer den Antrag nicht kennt, weiß nicht einmal, dass es ihn gibt.
Das ist keine böse Absicht. Es ist ein Strukturproblem. Zugang skaliert mit organisatorischer Kapazität. Organisatorische Kapazität korreliert mit Größe und Ressourcen. Wer am meisten Schutz braucht – veraltete Systeme, dünne IT-Besetzung, knappe Budgets – hat die schlechtesten Karten im Zugangsregime.
Konkret bedeutet das: Es entsteht eine Zwei-Klassen-Cyberabwehr. Oben: Konzerne und Behörden mit Frontier-KI-gestützter Schwachstellenanalyse. Unten: Kommunale Infrastruktur, die mit den Werkzeugen von gestern die Angriffe von morgen abwehren soll.
Für Organisationen: Die neue Abhängigkeit
CrowdStrike, Palo Alto Networks und Zscaler sind nicht nur Nutzer der neuen Modelle. Sie sind Partner im Ökosystem. Sie integrieren Frontier-KI in ihre Produkte und verkaufen den Zugang weiter – an ihre eigenen Kunden.
Forrester beschrieb die Folge: Wer eine formale Partnerschaft mit Anthropic oder OpenAI eingeht, gewinnt Einfluss auf Governance und Produktgestaltung. Wer die Beziehung informell lässt, akzeptiert Abhängigkeit ohne Mitsprache.²¹
Für IT-Entscheider in Unternehmen verschiebt sich damit eine Grundfrage. Bisher lautete sie: Welches Sicherheitsprodukt passt zu unserer Infrastruktur? Künftig lautet sie: Welchem Ökosystem schließen wir uns an – und welche Zugangsstufe bekommen wir dort?
Das ist ein neuer Typus von Vendor Lock-in. Nicht über Dateiformate oder API-Standards, sondern über Vertrauensstufen und Verifikationsprozesse. Wer einmal im Trusted-Access-Programm eines Anbieters ist, wechselt nicht einfach – weil die Verifikation beim Konkurrenten von vorn beginnt.
Für Gesellschaft und Politik: Wer kontrolliert die Kontrolle?
Die tiefere Verschiebung betrifft nicht einzelne Produkte. Sie betrifft die Rollenverteilung.
KI-Firmen übernehmen Funktionen, die in traditionellen Sicherheitsarchitekturen staatlich verankert waren. Sie definieren, wer als "trusted" gilt. Sie entscheiden, welche Organisationen Zugang zu welcher Fähigkeitsstufe bekommen. Sie verhandeln direkt mit Regierungen – nicht als Auftragnehmer, sondern als Architekten des Zugangsrahmens.
Das Pentagon bezeichnete Anthropic als "supply chain risk to national security" – nachdem Anthropic sich geweigert hatte, das Militär ohne Einschränkungen auf Claude zugreifen zu lassen. Ein Bundesgericht blockierte die Einstufung als verfassungswidrig.¹⁰ Gleichzeitig testete die NSA Mythos auf klassifizierten Netzwerken. Und das Weiße Haus arbeitete an einer Richtlinie, die es Bundesbehörden ermöglichen soll, die Pentagon-Einstufung zu umgehen und Mythos dennoch zu nutzen.²² Am 1. Mai – dem Tag, an dem dieser Artikel erscheint – schloss das Pentagon Verträge mit sieben Tech-Firmen über KI-Nutzung in klassifizierten Netzwerken. Anthropic war nicht dabei.²³
Der Staat widerspricht sich nicht aus Versehen. Verschiedene Teile des Staates verfolgen verschiedene Interessen – Verteidigungsministerium, Geheimdienste, Weißes Haus, Kongress. Was nach Widerspruch aussieht, ist institutionelle Arbeitsteilung unter Druck.
Die politische Frage, die daraus folgt, wird selten gestellt: Nach welchen Kriterien wird "Verteidiger" definiert? Wer prüft die Prüfer? Und gibt es ein demokratisch legitimiertes Gegenstück zu Trusted Access – oder bleibt die Definition von Vertrauen eine Unternehmensentscheidung?
Was offen bleibt
Im April 2026 hat sich etwas verschoben. Nicht schlagartig, nicht durch ein einzelnes Ereignis – aber sichtbar genug, um es zu benennen.
Zwei Unternehmen haben Modelle gebaut, die autonom Schwachstellen finden, verketten und ausnutzen können. Beide haben den öffentlichen Zugang beschränkt. Beide verhandeln mit Regierungen. Beide definieren, wer "vertrauenswürdig" genug ist, um diese Werkzeuge zu nutzen. Und beide erzählen dabei eine Geschichte, die ihre eigene Rolle in einem günstigen Licht erscheinen lässt.
Das ist nicht verwerflich. Es ist erwartbar. Die Frage ist, was daraus folgt.
Was ungeklärt bleibt
OpenAI verspricht, den Zugang über Intermediäre bis zu Schulbezirken und Wasserwerken zu skalieren. Anthropic hat 100 Millionen Dollar für Glasswing bereitgestellt. Beide Programme existieren seit Wochen, nicht seit Jahren. Ob sie tatsächlich bei den Organisationen ankommen, die den größten Rückstand haben, wird sich erst zeigen. Die Ankündigung ist nicht die Umsetzung.
Dazu kommt: Das Regime, das sich gerade bildet, ist privat organisiert. Zwei Firmen setzen die Kriterien. Regierungen sind Kunden, Gesprächspartner und gelegentlich Störfaktoren – aber nicht Architekten. Gibt es einen Ort, an dem demokratisch darüber verhandelt wird, wer Zugang zu Frontier-Cyber-KI bekommt? Bisher nicht. Das House Homeland Security Committee hat erste Briefings bekommen.⁹ Das ist ein Anfang. Kein Ersatz.
Und die Modelle werden besser. Nicht in Jahren, in Monaten. AISI beobachtet seit August 2025 jeden Monat ein neues Frontier-Modell mit relevanten Cyber-Fähigkeiten.¹⁴ Die Frage ist nicht ob, sondern wann die nächste Stufe erreicht wird – Modelle, die nicht nur schwach gesicherte Labornetzwerke, sondern gehärtete reale Systeme angreifen können. Was dann?
Der blinde Fleck
Die gesamte Debatte dreht sich um zwei Länder: die USA und Großbritannien. Anthropic sitzt in San Francisco, OpenAI ebenfalls. AISI evaluiert aus London. Five Eyes werden gebrieft.
Aber Cyberangriffe kennen keine Ländergrenzen. Und die Organisationen, die am verwundbarsten sind – Krankenhäuser in Ländern mit schwacher IT-Infrastruktur, Behörden in Staaten ohne Cyber-Strategie, Open-Source-Projekte mit überlasteten Maintainern – haben keinen Platz in Trusted Access. Sie tauchen in keinem Partnerprogramm auf. Sie werden nicht gebrieft.
Anthropic selbst hat das Problem benannt: Die Arbeit an der Sicherung kritischer Infrastruktur könnte Jahre dauern. Frontier-KI-Fähigkeiten entwickeln sich in Monaten.⁵
Die Lücke zwischen diesen beiden Geschwindigkeiten ist der eigentliche Befund dieses Artikels.
Einladung
Dieser Text kann die Lücke nicht schließen. Er kann sie sichtbar machen. Wer in einem Unternehmen, einer Behörde oder einem Open-Source-Projekt Sicherheitsverantwortung trägt, steht vor einer konkreten Frage: Welchen Zugang habe ich – und welchen nicht?
Wie sollte ein öffentliches Gegenstück zu Trusted Access aussehen? Wer sollte darüber entscheiden, welche Organisationen Zugang zu den stärksten Verteidigungswerkzeugen bekommen? Und nach welchen Kriterien – Größe, Relevanz, Verwundbarkeit, Zahlungsfähigkeit?
Die Debatte darüber hat noch nicht begonnen. Sie sollte.
Vertiefung: Risiko als Beobachtungskategorie
Dieser Abschnitt vertieft die theoretischen Grundlagen des Artikels. Er ist nicht nötig, um die Argumentation zu verstehen – aber er macht die Vereinfachungen sichtbar, die in den vorherigen Abschnitten unvermeidlich waren.
Luhmann vs. Beck: Zwei Risikobegriffe, zwei verschiedene Diagnosen
Der Artikel arbeitet mit Luhmanns Unterscheidung von Risiko und Gefahr.¹¹ Diese Unterscheidung ist nicht trivial – und sie führt zu einem anderen Befund als die bekanntere Alternative.
Ulrich Becks "Risikogesellschaft" (1986) beschreibt Risiko als objektives Nebenprodukt industrieller Modernisierung.²⁴ Radioaktivität, Chemieunfälle, Klimawandel – diese Risiken existieren, unabhängig davon, wer sie beobachtet. Becks Pointe: Die Gesellschaft produziert Gefahren, die sie mit ihren eigenen Institutionen nicht mehr kontrollieren kann. Risiko ist bei Beck eine Eigenschaft der Welt.
Luhmann dreht das um. Risiko ist bei ihm keine Eigenschaft der Welt, sondern eine Beobachtungskategorie.¹¹ Dieselbe Situation kann Risiko oder Gefahr sein – je nachdem, wer beobachtet. Für Anthropic ist die Veröffentlichung von Mythos ein Risiko: eine eigene Entscheidung mit ungewissen Folgen. Für ein Krankenhaus in Sachsen-Anhalt, das keine Kontrolle über diese Entscheidung hat, ist die Existenz solcher Modelle eine Gefahr – etwas, das von außen kommt.
Der Unterschied ist nicht akademisch. Er verändert die Analyse.
In Becks Rahmen wäre die Frage: Wie begrenzen wir die objektive Gefährlichkeit der Modelle? Die Antwort liefe auf Regulierung hinaus – Verbote, Auflagen, staatliche Kontrolle.
In Luhmanns Rahmen lautet die Frage anders: Wer beobachtet das Risiko, und welche Folgeentscheidungen ergeben sich aus dieser Beobachtung? Anthropic beobachtet Risiko und entscheidet: eingeschränkter Zugang. OpenAI beobachtet dasselbe Risiko und entscheidet: gestufter Zugang. AISI beobachtet und entscheidet: messen und veröffentlichen. Jede Beobachtung erzeugt eine andere Anschlussentscheidung. Keine davon ist falsch. Aber jede erzeugt neue Risiken für andere.
Luhmann nennt das Risikotransformation: Die Entscheidung, ein Risiko zu reduzieren, erzeugt neue Risiken an anderer Stelle.¹¹ Anthropic reduziert das Risiko der öffentlichen Verfügbarkeit – und erzeugt das Risiko, dass nur Großorganisationen Zugang bekommen. OpenAI reduziert das Risiko der Exklusivität – und erzeugt das Risiko, dass gestufte Verifikation nicht schnell genug skaliert. Jede Lösung verschiebt das Problem.
Das ist kein Zynismus. Es ist eine strukturelle Beobachtung. Und sie erklärt, warum das Cyber-KI-Sicherheitsregime sich nicht "lösen" lässt, sondern nur in verschiedene Formen von Unzulänglichkeit überführt werden kann.
Methodische Reflexion: Was Benchmarks können und was nicht
AISI-Evaluationen sind derzeit die beste verfügbare Grundlage für die Einschätzung von Cyber-Fähigkeiten. Aber sie haben systematische Grenzen, die über die im Artikel genannten Caveats hinausgehen.
Das Messartefakt-Problem. AISI misst Fähigkeiten in kontrollierten Umgebungen. Die Ergebnisse beschreiben, was ein Modell kann, wenn es einen spezifischen Auftrag erhält, Netzwerkzugang hat und keine Gegenmaßnahmen existieren.⁶ Die Modelle könnten in der Praxis schlechter abschneiden – weil Verteidiger reagieren. Sie könnten aber auch besser abschneiden – weil reale Netzwerke oft weniger konsistent gewartet werden als Simulationen unterstellen.
AISI erkennt das Problem und arbeitet an Evaluationsumgebungen mit aktiven Verteidigern und gehärteten Zielen.⁶ Bis diese existieren, beschreiben alle veröffentlichten Zahlen eine Untergrenze des Risikos, nicht seine tatsächliche Ausprägung in realen Netzwerken.
Das Benchmark-als-Markt-Problem. Sobald AISI veröffentlicht, dass ein Modell "eines der stärksten getesteten" ist, wird das zur Schlagzeile – und zum Verkaufsargument.⁸ Benchmarks sollen Risiken sichtbar machen. Aber sie erzeugen gleichzeitig Ranglisten, und Ranglisten erzeugen Wettbewerb. Das ist kein Fehler der AISI. Es ist eine unvermeidliche Doppelfunktion jeder öffentlichen Leistungsmessung. Wer misst, macht vergleichbar. Wer vergleichbar macht, erzeugt Märkte.
Das Distillationsproblem. Die Debatte konzentriert sich auf die Zugangskontrolle bei Frontier-Modellen. Aber Fähigkeiten diffundieren. Das NCSC verweist darauf, dass Fähigkeiten aus Frontier-Modellen über Distillation in kleinere, günstigere und frei verfügbare Modelle übertragen werden können.¹³ AISLE zeigte, dass Teile der Mythos-Ergebnisse mit offenen Modellen reproduzierbar sind – mit der Einschränkung, dass Erkennung und autonome Ausnutzung verschiedene Fähigkeitsstufen darstellen.¹⁹ Die Zugangskontrolle bei Anthropic und OpenAI mag Missbrauch verzögern. Verhindern kann sie ihn nicht, solange die zugrundeliegenden Fähigkeiten auch über andere Wege erreichbar sind.
Was das für den Artikel bedeutet
Die Vereinfachungen in den vorherigen Abschnitten waren notwendig – für Lesbarkeit, für Zugänglichkeit. Aber sie haben einen Preis.
Der Kreislauf (Modelle → Risiken → Kontrolle → Märkte → Modelle) suggeriert eine lineare Kette. Systemtheoretisch operieren die Systeme gleichzeitig. Die Darstellung als Kreislauf dient der Verständlichkeit, nicht der Präzision.
Die AISI-Zahlen (3/10, 2/10, 73%, 71,4%) wirken wie harte Befunde. In Wirklichkeit beschreiben sie Momentaufnahmen in einem sich schnell bewegenden Feld. Zwischen der Mythos-Evaluation und der GPT-5.5-Evaluation lagen zwei Wochen. In zwei Wochen kann sich das Leistungsbild grundlegend verschieben.
Der Artikel bildet den Stand vom 1. Mai 2026 ab. Nicht mehr, nicht weniger.
Quellenverzeichnis
¹ TechCrunch: "Sam Altman throws shade at Anthropic's cyber model, Mythos: 'fear-based marketing'." 21. April 2026.
² TechCrunch: "After dissing Anthropic for limiting Mythos, OpenAI restricts access to Cyber, too." 30. April 2026.
³ Ebd.
⁴ Anthropic: "Project Glasswing: Securing critical software for the AI era." 7. April 2026. anthropic.com/glasswing
⁵ Ebd. sowie Anthropic: "Project Glasswing." anthropic.com/project/glasswing
⁶ AI Security Institute (AISI): "Our evaluation of Claude Mythos Preview's cyber capabilities." 13. April 2026. aisi.gov.uk
⁷ OpenAI: "Trusted access for the next era of cyber defense." 14. April 2026. openai.com
⁸ AI Security Institute (AISI): "Our evaluation of OpenAI's GPT-5.5 cyber capabilities." 30. April 2026. aisi.gov.uk
⁹ Axios: "Exclusive: OpenAI briefs feds and Five Eyes on new cyber product." 22. April 2026.
¹⁰ Axios: "Exclusive: OpenAI, Anthropic meet with House Homeland Security behind closed doors on cyber threats." 28. April 2026. Sowie CNN: "Judge blocks Pentagon's effort to 'punish' Anthropic." 26. März 2026.
¹¹ Luhmann, Niklas: Soziologie des Risikos. De Gruyter, Berlin/New York 1991. Sowie ders.: Soziale Systeme. Grundriß einer allgemeinen Theorie. Suhrkamp, Frankfurt am Main 1984.
¹² OpenAI: "Accelerating the cyber defense ecosystem that protects us all." 16. April 2026. openai.com
¹³ National Cyber Security Centre (NCSC): "Why cyber defenders need to be ready for frontier AI." 30. März 2026. ncsc.gov.uk
¹⁴ AISI, Evaluation Mythos Preview (a.a.O.). Detailanalyse: Elephas Resources, "Claude Mythos Preview: First AI to Complete a 32-Step Autonomous Cyber Attack." April 2026.
¹⁵ Anthropic, Frontier Red Team: "Claude Mythos Preview." 7. April 2026. red.anthropic.com/2026/mythos-preview/
¹⁶ NCSC/AISI: "Why cyber defenders need to be ready for frontier AI" (a.a.O.). Kosten beziehen sich auf Modelle vor März 2026, nicht auf Mythos.
¹⁷ OpenAI: GPT-5.5 System Card. April 2026. deploymentsafety.openai.com/gpt-5-5
¹⁸ Schneier, Bruce: "On Anthropic's Mythos Preview and Project Glasswing." schneier.com, April 2026. Sowie ders.: "Mythos and Cybersecurity." schneier.com, April 2026.
¹⁹ AISLE: "AI Cybersecurity After Mythos: The Jagged Frontier." aisle.com/blog, April 2026.
²⁰ OpenAI: "Cybersecurity in the Intelligence Age: An Action Plan." 30. April 2026. Sowie CNN: "OpenAI wants to put its most powerful model at all levels of government." 29. April 2026.
²¹ Forrester (Pollard, Mellen, Burn, Blankenship, Scott): "Project Glasswing: The 10 Consequences Nobody's Writing About Yet." 10. April 2026.
²² Axios: "Trump officials draft plan to bring Anthropic back amid Pentagon fight." 29. April 2026.
²³ CNN: "Pentagon strikes deals with 7 Big Tech companies after shunning Anthropic." 1. Mai 2026.
²⁴ Beck, Ulrich: Risikogesellschaft. Auf dem Weg in eine andere Moderne. Suhrkamp, Frankfurt am Main 1986.





